| Features | Spark | Hadoop |
|---|---|---|
| Data processing | Part of Hadoop, hence batch processing | Batch Processing even for high volumes |
| Streaming Engine | Apache spark streaming - micro-batches | Map-Reduce |
| Data Flow | Direct Acyclic Graph-DAG | Map-Reduce |
| Computation Model | Collect and process | Map-Reduce batch-oriented model |
| Performance | Slow due to batch processing | Slow due to batch processing |
| Memory Management | Automatic memory management in the latest release | Dynamic and static - Configurable |
| Fault Tolerance | Recovery available without extra code | Highly fault-tolerant due to Map-Reduce |
| Scalability | Highly scalable - spark Cluster(8000 Nodes) | Highly scalable - Produces a large number of nodes |
| Apache Spark | MapReduce |
|---|---|
| Spark processes data in batches as well as in real-time | MapReduce processes data in batches only |
| Spark runs almost 100 times faster than Hadoop MapReduce | Hadoop MapReduce is slower when it comes to large scale data processing |
| Spark stores data in the RAM i.e. in-memory. So, it is easier to retrieve it | Hadoop MapReduce data is stored in HDFS and hence takes a long time to retrieve the data |
| Spark provides caching and in-memory data storage | Hadoop is highly disk-dependent |
method val DataArray = Array(2,4,6,8,10)
val DataRDD = sc.parallelize(DataArray)map() is called on an RDD, the operation is not performed instantly. Transformations in Spark are not evaluated until you perform an action, which aids in optimizing the overall data processing workflow, known as lazy evaluation. | Repartition | Coalesce |
|---|---|
| Usage repartition can increase/decrease the number of data partitions. | Spark coalesce can only reduce the number of data partitions. |
| Repartition creates new data partitions and performs a full shuffle of evenly distributed data. | Coalesce makes use of already existing partitions to reduce the amount of shuffled data unevenly. |
| Repartition internally calls coalesce with shuffle parameter thereby making it slower than coalesce. | Coalesce is faster than repartition. However, if there are unequal-sized data partitions, the speed might be slightly slower. |
map() and filter() are examples of transformations, where the former applies the function passed to it on each element of RDD and results into another RDD. The filter() creates a new RDD by selecting elements from current RDD that pass function argument.val rawData=sc.textFile("path to/movies.txt")
val moviesData=rawData.map(x=>x.split(" "))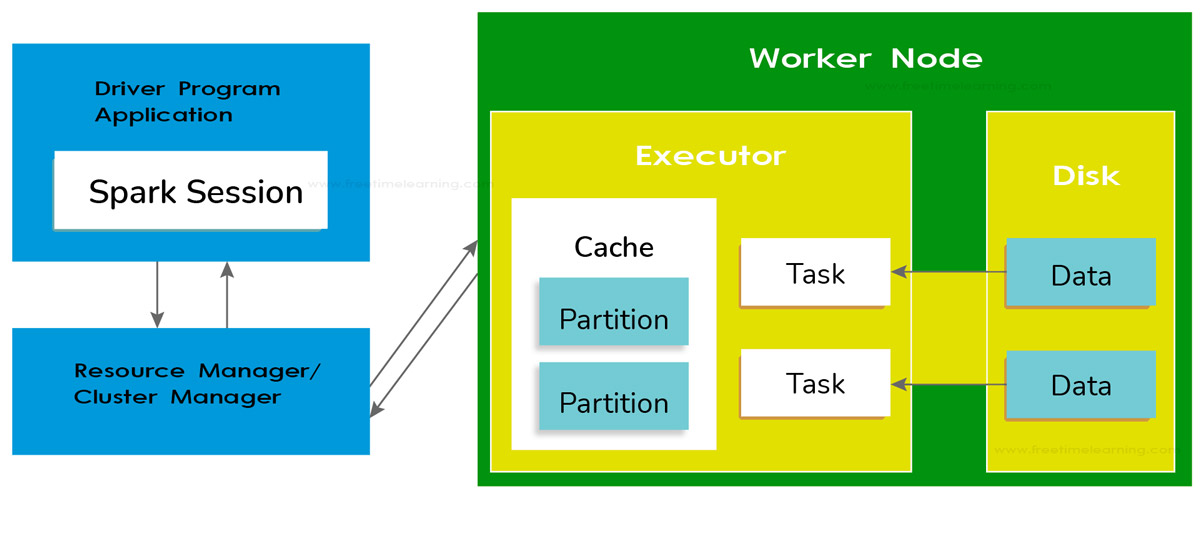
hive> set spark.home=/location/to/sparkHome;
hive> set hive.execution.engine=spark;Vectors.sparse(7,Array(0,1,2,3,4,5,6),Array(1650d,50000d,800d,3.0,3.0,2009,95054))import com.mapr.db.spark.sql._
val df = sc.loadFromMapRDB(<table-name>)
.where(field(“first_name”) === “Peter”)
.select(“_id”, “first_name”).toDF()def createDataFrame(RDD, schema:StructType)toDS():Dataset[T]
toDF():DataFrame
toDF(columName:String*):DataFrame
spark.executor.memory that belongs to the -executor-memory flag. Every Spark applications have one allocated executor on each worker node it runs. The executor memory is a measure of the memory consumed by the worker node that the application utilizes. map() or reduce() too many times. This overloading of service is also possible while using Spark.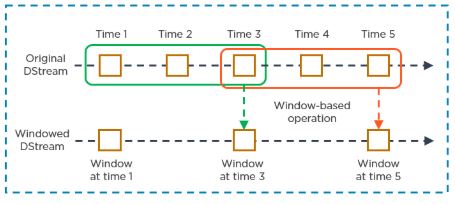
DISK_ONLY : Stores the RDD partitions only on the diskMEMORY_ONLY_SER : Stores the RDD as serialized Java objects with a one-byte array per partitionMEMORY_ONLY : Stores the RDD as deserialized Java objects in the JVM. If the RDD is not able to fit in the memory available, some partitions won’t be cachedOFF_HEAP : Works like MEMORY_ONLY_SER but stores the data in off-heap memoryMEMORY_AND_DISK : Stores RDD as deserialized Java objects in the JVM. In case the RDD is not able to fit in the memory, additional partitions are stored on the diskMEMORY_AND_DISK_SER : Identical to MEMORY_ONLY_SER with the exception of storing partitions not able to fit in the memory to the diskNumber of nodes = 10
Number of cores in each node = 15 cores
RAM of each node = 61GB Number of Cores = number of concurrent tasks that can be run parallelly by the executor.
The optimal value as part of a general rule of thumb is 5.Number of executors = Number of cores/Concurrent Task
= 15/5
= 3
Number of executors = Number of nodes * Number of executor in each node
= 10 * 3
= 30 executors per Spark jobfiler() is to develop a new RDD by selecting the various elements from the existing RDD, which passes the function argument.
Spark.clener.ttl” to trigger automated clean-ups in Spark is by dividing the long-running jobs into different batches and writing the intermediary results on the disk.
| Criteria | Spark Datasets | Spark Dataframes | Spark RDDs |
|---|---|---|---|
| Representation of Data | Spark Datasets is a combination of Dataframes and RDDs with features like static type safety and object-oriented interfaces. | Spark Dataframe is a distributed collection of data that is organized into named columns. | Spark RDDs are a distributed collection of data without schema. |
| Optimization | Datasets make use of catalyst optimizers for optimization. | Dataframes also makes use of catalyst optimizer for optimization. | There is no built-in optimization engine. |
| Schema Projection | Datasets find out schema automatically using SQL Engine. | Dataframes also find the schema automatically. | Schema needs to be defined manually in RDDs. |
| Aggregation Speed | Dataset aggregation is faster than RDD but slower than Dataframes. | Aggregations are faster in Dataframes due to the provision of easy and powerful APIs. | RDDs are slower than both the Dataframes and the Datasets while performing even simple operations like data grouping. |
val cacheDf = dframe.cache()​
val persistDf = dframe.persist(StorageLevel.MEMORY_ONLY)| map() | flatMap() |
|---|---|
| A map function returns a new DStream by passing each element of the source DStream through a function func | It is similar to the map function and applies to each element of RDD and it returns the result as a new RDD |
| Spark Map function takes one element as an input process it according to custom code (specified by the developer) and returns one element at a time | FlatMap allows returning 0, 1, or more elements from the map function. In the FlatMap operation |
