Neo4j is an open source NOSQL graph database, implemented in Java. It saves data structured in graphs rather than in tables.Neo4j was started in 2003, it has been publicly available since 2007. The source code and issue tracking of Neo4j is available on GitHub, with support readily available on Stack Overflow and the Neo4j Google group. Neo4J is called graph database because it stores data structure in graph instead of in tables. Neo4j 1.0 and it was released in Feb, 2010. | RDBMS | Graph Database |
| Tables | Graphs |
| Rows | Nodes |
| Columns and Data | Properties and its Values |
| Constraints | Relationships |
| Joins | Traversal |
delete/remove entire graph directory you can use command rm –rf data/* as such Neo4j is not storing anything outside that.START n=node:node_auto_index(name='abc') RETURN n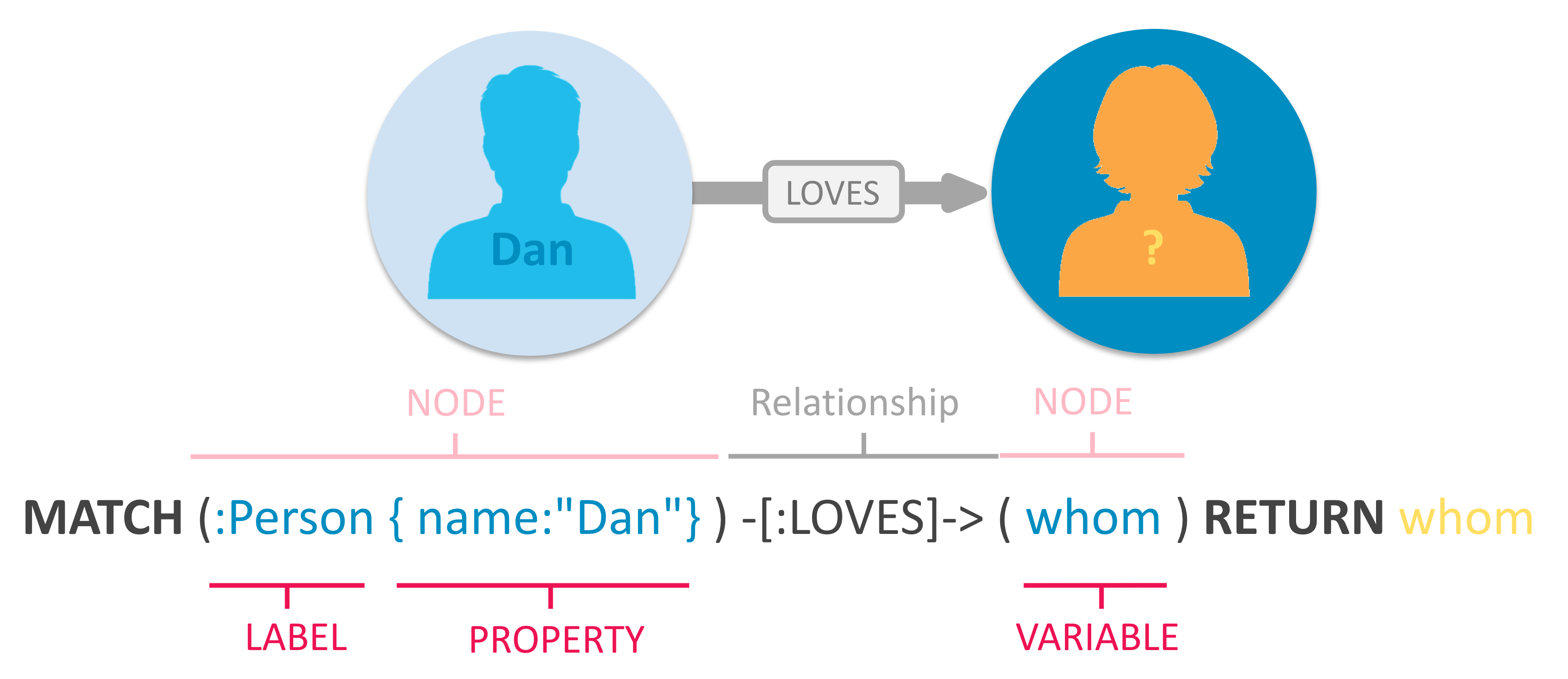
(nodes)-[:ARE_CONNECTED_TO]->(otherNodes) using rounded brackets for circular (nodes), and -[:ARROWS]-> for relationships. When you write a query, you draw a graph pattern through your data.MATCH (actor:Person)-[:ACTED_IN]->(movie:Movie)
WHERE movie.title STARTS WITH "S"
RETURN movie.title AS title, collect(actor.name) AS cast
ORDER BY title ASC LIMIT 10;| Neo4j | MongoDB |
| A primary database model is Graph DBMS. | A primary database model is Document Store. |
| Implemented in Java and Scala.. | Implemented in C++ Language. |
| Neo4j has an optional schema. | MongoDB is schema-free. |
| It uses Cypher query language, Java API, Neo4j-OGM, Spring Data Neo4j, TinkerPop 3 | Proprietary protocol using JSON |
| Uses triggers | No triggers are used |
MATCH (n:Person { name: 'UNKNOWN' })
DELETE nMATCH (n)
DETACH DELETE n ​MATCH (n { name: 'Andres' })
DETACH DELETE nMATCH (n { name: 'Andres' })-[r:KNOWS]->()
DELETE rRESTful API, you can query over the web, or you can run it locally. It runs in the Heroku or Cloud. RETURN or UPDATE clause. It cannot be used alone otherwise it will give error.MATCH
(
<node-name>:<label-name>
) MATCH command cannot be used alone to fetch data from the database otherwise it will show invalid syntax error.MATCH (node:label{properties . . . . . . . . . . . . . . })
SET node.property = value
RETURN node