
| ETL TOOLS | BI TOOLS |
|---|---|
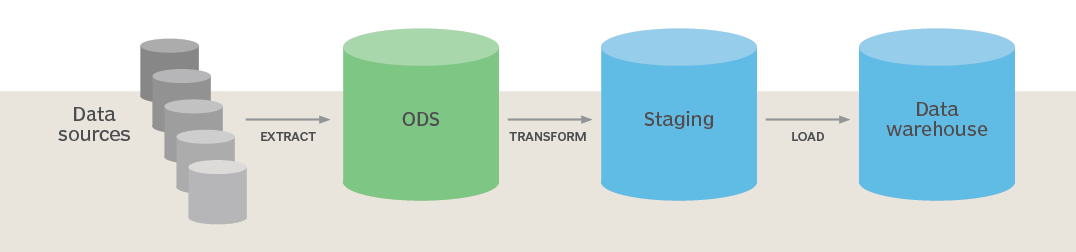
| The ETL tools are used to extract the data from different data sources, transform the data, and load it into a data warehouse system. | BI tools are used to generate interactive and ad-hoc reports for end-users, data visualization for monthly, quarterly, and annual board meetings. |
| Most commonly ETL tools are Informatica, SAP BO data service, Microsoft SSIS, Oracle Data Integrator (ODI) Clover ETL Open Source, etc. | Most commonly BI tools are SAP Lumira, IBM Cognos, Microsoft BI platform, Tableau, Oracle Business Intelligence Enterprise Edition, etc. |
| ETL Testing | Manual Testing |
|---|---|
| The test is an automated process, which means that no special technical knowledge is needed aside from understanding the software. | It requires technical expertise in SQL and Shell scripting since it is a manual process. |
| It is extremely fast and systematic, and it delivers excellent results. | In addition to being time-consuming, it is highly prone to errors. |
| Databases and their counts are central to ETL testing. | Manual testing focuses on the program's functionality. |
| Metadata is included and can easily be altered. | It lacks metadata, and changes require more effort. |
| It is concerned with error handling, log summary, and load progress, which eases the developer's and maintainer's workload. | From a maintenance perspective, it requires maximum effort. |
| It is very good at handling historical data. | As data increases, processing time decreases. |
| OLTP | OLAP |
|---|---|
| OLTP stands for Online Transactional Processing. | OLAP stands for Online Analytical Processing. |
| OLTP is a relational database, and it is used to manage the day to day transaction. | OLAP is a multidimensional system, and it is also called a data warehouse. |
| Power Mart | Power Center |
|---|---|
| It only processes small amounts of data and is considered good if the processing requirements are low. | It is considered good when the amount of data to be processed is high, as it processes bulk data in a short period of time. |
| ERP sources are not supported. | ERP sources such as SAP, PeopleSoft, etc. are supported. |
| Currently, it only supports local repositories. | Local and global repositories are supported. |
| There are no specifications for turning a local repository into a global repository. | It is capable of converting local repositories into global ones. |
| Session partitions are not supported. | To improve the performance of ETL transactions, it supports session partitioning. |
| Cust_ID | Prod_ID | Time_ID | No. of units sold |
|---|---|---|---|
| 101 | 24 | 1 | 25 |
| 102 | 25 | 2 | 15 |
| 103 | 26 | 3 | 30 |
| Cust_ID | Cust_Name | Gender |
|---|---|---|
| 101 | Sana | F |
| 102 | Jass | M |
| Data Warehousing | Data Mining |
|---|---|
| It involves gathering all relevant data for analytics in one place. | Data is extracted from large datasets using this method. |
| Data extraction and storage assist in facilitating easier reporting. | It identifies patterns by using pattern recognition techniques. |
| Engineers are solely responsible for data warehousing, and data is periodically stored. | Data mining is carried out by business users in conjunction with engineers, and data is analyzed regularly. |
| In addition to making data mining easier and more convenient, it helps sort and upload important data to databases. | Analyzing information and data is made easier. |
| It is possible to accumulate a large amount of irrelevant and unnecessary data. Loss and erasure of data can also be problematic. | Not doing it correctly can create data breaches and hacking since data mining isn't always 100% accurate. |
| Data mining cannot take place without this process, since it compiles and organizes data into a common database. | Because the process requires compiled data, it always takes place after data warehousing. |
| Data warehouses simplify every type of business data. | Comparatively, data mining techniques are inexpensive. |

| Connected Lookup | Unconnected Lookup |
|---|---|
| Connected lookup participates in mapping | It is used when lookup function is used instead of an expression transformation while mapping |
| Multiple values can be returned | Only returns one output port |
| It can be connected to another transformations and returns a value | Another transformation cannot be connected |
| Static or dynamic cache can be used for connected Lookup | Unconnected as only static cache |
| Connected lookup supports user defined default values | Unconnected look up does not support user defined default values |
| In Connected Lookup multiple column can be return from the same row or insert into dynamic lookup cache | Unconnected lookup designate one return port and returns one column from each row |