
| Characteristics | Apache Kafka | RabbitMQ |
|---|---|---|
| Architecture | Kafka uses a partitioned log model, which combines messaging queue and publish subscribe approaches. | RabbitMQ uses a messaging queue. |
| Scalability | Kafka provides scalability by allowing partitions to be distributed across different servers. | Increase the number of consumers to the queue to scale out processing across those competing consumers. |
| Message retention | Policy based, for example messages may be stored for one day. The user can configure this retention window. | Acknowledgement based, meaning messages are deleted as they are consumed. |
| Multiple consumers | Multiple consumers can subscribe to the same topic, because Kafka allows the same message to be replayed for a given window of time. | Multiple consumers cannot all receive the same message, because messages are removed as they are consumed. |
| Replication | Topics are automatically replicated, but the user can manually configure topics to not be replicated. | Messages are not automatically replicated, but the user can manually configure them to be replicated. |
| Message ordering | Each consumer receives information in order because of the partitioned log architecture. | Messages are delivered to consumers in the order of their arrival to the queue. If there are competing consumers, each consumer will process a subset of that message. |
| Protocols | Kafka uses a binary protocol over TCP. | Advanced messaging queue protocol (AMQP) with support via plugins: MQTT, STOMP. |
$bin/zookeeper-server-start.sh config/zookeeper.properties$ bin/kafka-server-start.sh config/server.properties | Apache Kafka | Apache Flume |
|---|---|
| Apache Kafka is a distributed data store or a data system. | Apache Flume is a distributed, available, and reliable system. |
| Apache Kafka is optimized for ingesting and processing streaming data in real-time. | Apache Flume can efficiently collect, aggregate and move a large amount of log data from many different sources to a centralized data store. |
| Apache Kafka is easy to scale. | Apache Flume is not scalable as Kafka. It is not easy to scale. |
| It is working as a pull model. | It is working as a push model. |
| It is a highly available, fault-tolerant, efficient and scalable messaging system. It also supports automatic recovery. | It is specially designed for Hadoop. In case of flume-agent failure, it is possible to lose events in the channel. |
| Apache Kafka runs as a cluster and easily handles the incoming high volume data streams in real-time. | Apache Flume is a tool to collect log data from distributed web servers. |
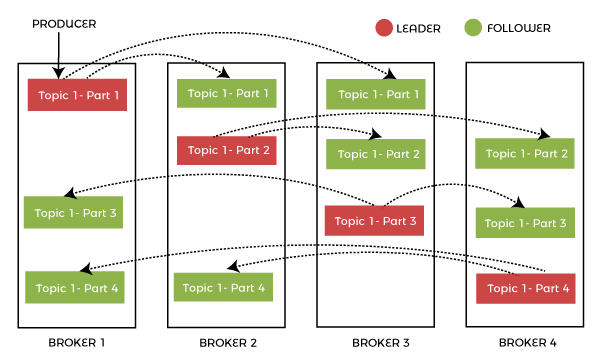
| Apache Kafka treats each topic partition as an ordered set of messages. | Apache Flume takes in streaming data from multiple sources for storage and analysis, which is used in Hadoop. |
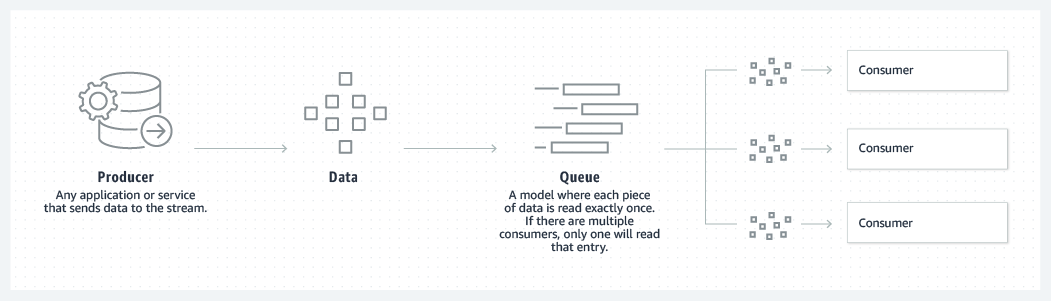
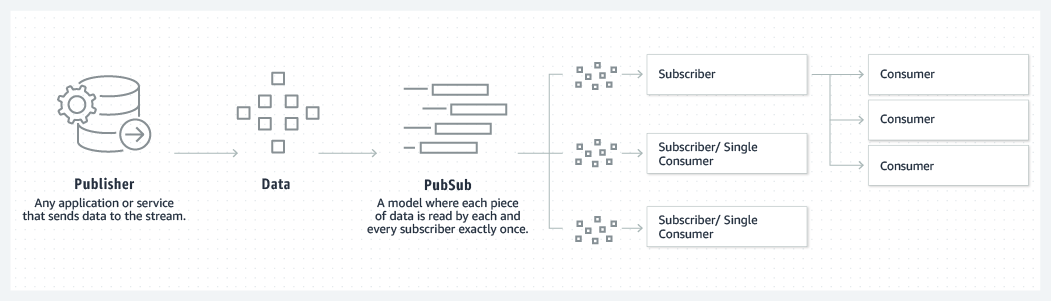
Log Anatomy is a way to view a partition. We view the log as the partitions, and a data source writes messages to the log. It facilitates that one or more consumers read that data from the log at any time they want. It specifies that the data source can write a log, and the log is being read by consumers at different offsets simultaneously. | Redis | Kafka |
|---|---|
| Push-based message delivery is supported by Redis. This means that messages published to Redis will be distributed to consumers automatically. | Pull-based message delivery is supported by Kafka. The messages published to the Kafka broker are not automatically sent to the consumers; instead, consumers must pull the messages when they are ready. |
| Message retention is not supported by Redis. The communications are destroyed once they have been delivered to the recipients. | In its log, Kafka allows for message preservation. |
| Parallel processing is not supported by Redis. | Multiple consumers in a consumer group can consume partitions of the topic concurrently because of the Kafka's partitioning feature. |
| Redis can not manage vast amounts of data because it's an in-memory database. | Kafka can handle massive amounts of data since it uses disc space as its primary storage. |
| Because Redis is an in-memory store, it is much faster than Kafka. | Because Kafka stores data on disc, it is slower than Redis. |
import org.apache.kafka.clients.consumer.ConsumerRecordimport org.apache.kafka.common.serialization.StringDeserializerimport org.apache.spark.streaming.kafka010._import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistentimport org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribetry {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
{
log.debug("topic = %s, partition = %d, offset = %d,"
customer = %s, country = %s\n",
record.topic(), record.partition(), record.offset(),
record.key(), record.value());
int updatedCount = 1;
if (custCountryMap.countainsValue(record.value())) {
updatedCount = custCountryMap.get(record.value()) + 1;
}
custCountryMap.put(record.value(), updatedCount)
JSONObject json = new JSONObject(custCountryMap);
System.out.println(json.toString(4))close() function before exiting. This ensures that it closes the active network connections and sockets. This function also triggers rebalancing at the same time rather than waiting for consumer group co-ordinator to find the same and assign partitions to other consumers. | Java Messaging Service(JMS) | Kafka |
|---|---|
| The push model is used to deliver the messages. Consumers receive messages on a regular basis. | A pull mechanism is used in the delivery method. When consumers are ready to receive the messages, they pull them. |
| When the JMS queue receives confirmation from the consumer that the message has been received, it is permanently destroyed. | Even after the consumer has viewed the communications, they are maintained for a specified length of time. |
| JMS is better suited to multi-node clusters in very complicated systems. | Kafka is better suited to handling big amounts of data. |
| JMS is a FIFO queue that does not support any other type of ordering. | Kafka ensures that partitions are sent in the order in which they appeared in the message. |
| Kafka streams | Spark Streaming |
|---|---|
| Able to handle only real-time streams | Can handle real-time streams as well as batch processes. |
| The use of partitions and their replicas allows Kafka to be fault-tolerant. | Spark allows recovery of partitions using Cache and RDD (resilient distributed dataset) |
| Kafka does not provide any interactive modes. The broker simply consumes the data from the producer and waits for the client to read it. | Has interactive modes |
| Messages remain persistent in the Kafka log. | A dataframe or some other data structure has to be used to keep the data persistent. |