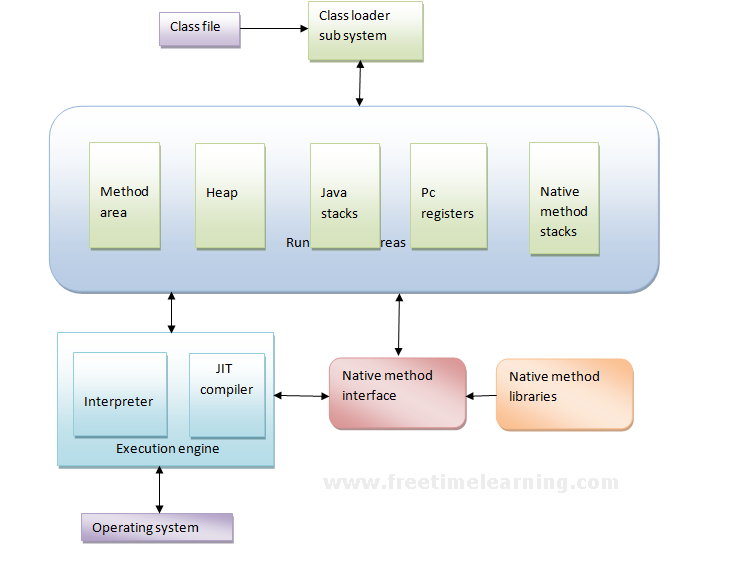
First of all, the .java program is converted into a .class file consisting of byte code instructions by the java compiler. Remember, this java compiler is outside the JVM. Now this .class file is given to the JVM.
Class loader subsystem: The class loader subsystem loads the .class file into memory. Then it verifies all byte code instructions whether all byte code instructions are proper or not. If it finds any instruction suspicious, the execution is rejected immediately.
Run time data areas: If the byte instructions are proper, then it allocates necessary memory to execute the program. This memory is divided into 5 parts, called run time data areas, which contain the data and results while running the program. These areas as follows:
1) Method area: Method area is the memory block, which stores the class code, code of the variables, and code of the methods in the java program.
2) Heap: This is the area where objects are created. Whenever JVM loads a class, a method and a heap area are immediately created in it.
3) Java Stacks: Method code is stored on method area. But while running a method, it needs some more memory to store the data and results. This memory is allotted on Java stacks. So, Java Stacks are memory areas where java methods are executed. While executing methods, a separate frame will be created in the java stack, where the method is executed. JVM uses a separate thread to execute each machine.
4) PC (Program Counter) registers: These are the registers (memory areas), which contain memory address of the instructions of the methods. If there are 3 methods, 3PC registers will be used to track the instructions of the methods.
5) Native method stacks: Java methods are executed on java stacks. Similarly, native methods are executed on Native method stacks. To execute the native methods, generally native method libraries (for example C/C++ header files) are required. These header files are located and connected to Jvm by a program, called Native method interface.
Execution engine: Execution engine contains Interpreter and JIT compiler, which are responsible for converting the byte code instructions into machine code so that the processor will execute them. Most of the JVM implementations use both the interpreter and JIT compiler simultaneously to convert the bytecode. This technique is also called adaptive optimizer.
Generally, any language (like c/c++, FORTRAN, COBOL, etc.) will use either an interpreter or a compiler to translate the source code into a machine code. But in JVM, we got interpreter and JIT compiler both working at the same time on byte code to translate it into machine code.