

Machine learning (ML) has become a cornerstone of technological advancement, powering everything from recommendation systems and fraud detection to self-driving cars and medical diagnosis. Understanding the core algorithms behind these intelligent systems is essential not only for data scientists but also for software engineers, analysts, and business professionals involved in data-driven decision-making.
This article provides an in-depth exploration of the most important machine learning algorithms, covering both supervised and unsupervised learning approaches. Each algorithm is explained with concepts, use cases, advantages, limitations, and when to use them.
Linear Regression is the simplest supervised learning algorithm used for predicting a continuous value. It assumes a linear relationship between the independent variable(s) and the dependent variable.

Predicting housing prices
Stock market forecasting
Sales prediction
Simple and interpretable
Fast training and prediction
Assumes linearity
Sensitive to outliers
Logistic Regression is used when the target variable is categorical. It predicts the probability that an instance belongs to a particular class.
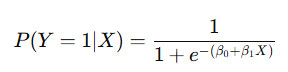
Email spam detection
Customer churn prediction
Disease diagnosis (yes/no)
Outputs probabilities
Efficient for binary classification
Can underperform with non-linear data
Not ideal for complex relationships
Decision Trees are non-parametric models that split data into branches based on feature thresholds. They are used for both classification and regression tasks.
Nodes represent features
Branches represent decisions
Leaves represent outcomes
Credit scoring
Medical decision support
Customer segmentation
Easy to interpret
Handles both numerical and categorical data
Prone to overfitting
Sensitive to data changes
Random Forest is an ensemble method that builds multiple decision trees and combines their results. It reduces overfitting by averaging predictions.
Randomly selects subsets of data and features
Trains multiple decision trees
Aggregates their results
Loan approval systems
Feature importance analysis
Image classification
Robust and accurate
Handles missing data well
Less interpretable than single decision trees
Computationally intensive
SVMs are supervised learning models that find the best boundary (hyperplane) that separates different classes in the feature space.
Margin maximization
Uses kernel trick for non-linearly separable data
Face detection
Bioinformatics (protein classification)
Text categorization
Works well on high-dimensional data
Effective with clear margin separation
Not suitable for large datasets
Requires careful tuning of kernel and parameters
k-NN is a lazy learning algorithm that stores all training data and predicts the class of a sample based on the majority class of its nearest neighbors.
Calculates distance (e.g., Euclidean)
Finds k closest neighbors
Predicts the majority class
Handwriting detection
Recommender systems
Anomaly detection
Simple and intuitive
No training phase required
Slow with large datasets
Sensitive to feature scaling
Naïve Bayes is a probabilistic classifier based on Bayes’ Theorem, assuming independence among features.
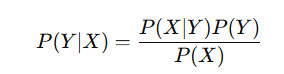
Spam filtering
Sentiment analysis
Document classification
Fast and efficient
Performs well on text data
Assumes feature independence
Not suitable for highly correlated features
GBM is an ensemble technique that builds models sequentially by correcting the errors of the previous models using gradient descent.
XGBoost
LightGBM
CatBoost
Kaggle competitions
Fraud detection
Predictive analytics
High predictive accuracy
Handles mixed data types
Longer training time
Prone to overfitting without tuning
K-Means is an unsupervised algorithm used for clustering simila
Reinforcement Learning (RL) is a type of learning where an agent learns to make decisions by interacting with an environment and receiving rewards.
Q-Learning
Deep Q-Networks (DQN)
Policy Gradient Methods
Robotics
Game AI (e.g., AlphaGo)
Autonomous vehicles
Learns optimal policies
Suitable for sequential decision tasks
Complex to implement
Requires lots of data and computation
| Problem Type | Recommended Algorithms |
|---|---|
| Regression | Linear Regression, Random Forest, Gradient Boosting |
| Classification | Logistic Regression, SVM, k-NN, Naïve Bayes, Random Forest |
| Clustering | K-Means, Hierarchical, DBSCAN |
| Dimensionality Reduction | PCA, t-SNE |
| Time Series Prediction | ARIMA, RNN, LSTM |
| Reinforcement Tasks | Q-Learning, DQN, Policy Gradient |
| Image Processing | CNN, Transfer Learning |
| Text/NLP Tasks | RNN, LSTM, Transformers |





