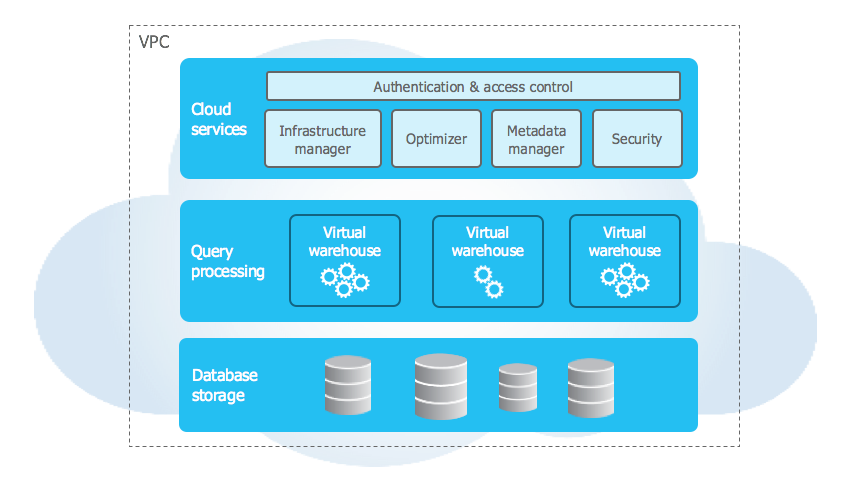
Snowflake has the following key features :
* With Snowflake, you can interact with the data cloud through a web interface. Users can navigate the web GUI to control their accounts, monitor resources, and monitor resources and system usage queries data, etc.
* Users can connect to Snowflake's data cloud using a wide range of client connectors and drivers. Among these connectors are Python Connector (an interface for writing Python applications to connect to Snowflake), Spark connector, NodeJS driver, .NET driver, JBDC driver for Java development, ODBC driver for C or C++ programming, etc.
* The core architecture of Snowflake enables it to operate on the public cloud, where it uses virtualized computing instances and efficient storage buckets for processing huge amounts of big data cost-effectively and scalable.
* Snowflake integrates with a number of big data tools, including business intelligence, machine learning, data integration, security, and governance tools.
* With advanced features such as simplicity, increased performance, high concurrency, and profitability, Snowflake is incomparable to other traditional data warehouse solutions.
* Snowflake supports the storage of both structured and semi-structured data (such as JSON, Avro, ORC, Parquet, and XML data).
* Snowflake automates cloud data management, security, governance, availability, and data resilience, resulting in reduced costs, no downtime, and better operational efficiency.
* With it, users can rapidly query data from a database, without having an impact on the underlying dataset. This allows them to receive data closer to real-time.
* Most DDL (Data Definition Language) and DML (Data Manipulation Language) commands in SQL are supported by the Snowflake data warehouse. Additionally, advanced DML, lateral views, transactions, stored procedures, etc., are also supported.