| Data Structure | Description |
| Vector | A vector is a sequence of data elements of the same basic type. Members in a vector are called components. |
| List | Lists are the R objects which contain elements of different types like − numbers, strings, vectors or another list inside it. |
| Matrix | A matrix is a two-dimensional data structure. Matrices are used to bind vectors from the same length. All the elements of a matrix must be of the same type (numeric, logical, character, complex). |
| Dataframe | A data frame is more generic than a matrix, i.e different columns can have different data types (numeric, character, logical, etc). It combines features of matrices and lists like a rectangular list. |
| R programming Language | Python programming language |
| Model Building is similar to Python | Model Building is similar to R. |
| Model Interpretability is good | Model Interpretability is not good |
| Production is not better than Python. | Production is good |
| R has good community support over Python. | Community Support is not better than R |
| Data Science Libraries are same as Python. | Data Science Libraries are same as R. |
| R has good data visualizations libraries and tools | Data visualization is not better than R |
| R has a steep learning curve. | Learning Curve in Python is easier than learning R. |
read.csv()” function and specify the path of the file.house<-read.csv("C:/Users/John/Desktop/house.csv")Sepal.Length, Sepal.Width, Petal.Length, Petal.Width and Species. We will calculate the mean of Sepal-Length across different species of iris flower using the mean() function from the mosaic package.mean(iris$Sepal.Length~iris$Species)3x3x2 array represents 2 matrices each of dimension 3x3. arima.sim(model=list(order=c(0,1,0)),n=40)->rw ts.plot(rw)arima.sim(model=list(order=c(0,0,0)),n=50)->wn| library() | require() |
Library() function gives an error message display, if the desired package cannot be loaded. |
Require() function is used inside function and throws a warning messages whenever a particular package is not Found |
| It loads the packages whether it is already loaded or not, | It just checks that it is loaded, or loads it if it isn’t (use in functions that rely on a certain package). The documentation explicitly states that neither function will reload an already loaded package. |
if(!require(package, character.only=T, quietly=T)) {
install.packages (package)
library(package, character.only=T)
}for(package in c('', '')) {
if(!require(package, character.only=T, quietly=T)) {
install.packages (package)
library(package, character.only=T)
}
}t.test() function..jpg)
with() function applies an expression to a dataset.#with(data,expression)By() function applies a function t each level of a factors.#by(data,factorlist,function)Subset() is used to select the variables and observations and sample() function is used to generate a random sample of the size n from a dataset. 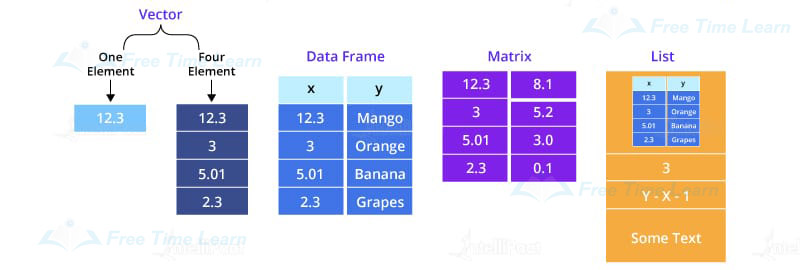
glm() is used to create the logistic regression. Mymatrix< - matrix (vector, nrow=r , ncol=c , byrow=FALSE,
dimnames = list ( char_vector_ rowname, char_vector_colnames))myTable = data.frame()
edit(myTable)apply() function : It helps to apply a function on rows or columns of a data frame. apply()lapply() function : It takes a list as an argument and applies a function to each element of the list by looping. lappy()sapply() function : It is more advanced version than lappy() however it works same as lappy(). It also takes a list as an argument and applies a function to each element of the list by looping. The only difference is in output generalization. Where lappy() returns a list as an output every time, sapply returns certain algorithms as output.sapply()tapply() function : It can be applied to vectors and factors. The data which contain different subgroup and we have to apply a specific function on each subgroup that time we can use it. tapply()mapply() function : It is a multivariate version of the sapply() function where we apply the same function to multiple arguments.mapply()dplyr” package are as follows :Select() function : Allows us to rapidly zoom in on a useful subset using operations that usually only work on numeric variable positions.group_by() function : It allows us to group by a modified columns. mutate() function : It is useful to add new columns that are functions of previous existing columns. filter() function : Allows us to select a subset of rows in a data frame. summarize() function : Allows us to collapses a data frame to a single row.relocate() function : Allows us to change the column order. slice() function : Allows us to select, remove and duplicate rows.desc() function : Allows us to arrange the column in descending order.> val1 <- 1:30
> for(val in val1){
+ if(val == 25){
+ next
+ }
+ print(val)
+ }%%" provides a reminder of the division of the first vector with the second, and the "%/%" gives the quotient of the division of the first vector with the second.
is.vector() is responsible for testing if the object is vector and therefore, has no attributes excluding names.>string_variable_name <- “R is an analytical language”
>print(string_variable_name)two tables in R by using CJ() function. It produces data. table out of the two vectors. This function does the Cartesian Product or Cross product of two data. tables. word() function in the R language. This function is mainly used for the extracted word from a string that is from the position that is specified as an argument. We can use String, start, end, sep, etc. as an argument. x and y. The correlation coefficient greater than zero indicates that a positive relationship, while a value less than zero indicates that a negative relationship. A negative correlation is also called inverse correlation which is a key concept in the creation of diversified portfolios that can better withstand portfolio volatility. Seq(4) means vector from 1 to 4 (c(1,2,3,4)) whereas seq_along(4) means a vector of the length(4) or 1(c(1)). >save(z,file=”z.Rdata”)>load(”z.Rdata”)
cluster.stats() function define in the fpc package that provides a method for comparing the similarity of two cluster solutions using different validation criteria, and the pvclust() function is defined in the pvclust package that provides p-values for hierarchical clustering.barlett.test() is used to provide a parametric k-sample test of the equality of variances. qda() function prints a quadratic discriminant function while lda() function print the discriminant functions based on the centered variable. auto.arima() function handle both the seasonal and non-seasonal ARIMA model and the principal() function used for rotating and extracting the principal components. S3 is used to overload any function. So that we can call the functions with different names, and it depends on the type of input parameter or the number of parameters, and the S4 is the most important characteristic of oops. However, this is a limitation, as it is quite difficult to debug. There is an optional reference class for S4. abline() function is add the reference line to a graph.abline(h=yvalues, v=xvalues)#This is how the data frame is created
> student_profile <- data.frame(
Name <-c(“Ray”, “Green”, “Justin”)
Age <- c(22,23,24)
Class <- c(6,7,8)
)
print(stuent_profile)predict() function, except it will choose sensible values by default. This simplifies to get a quick look at the model values. There are several arguments of it like model, data, on_training, nlevels, at, etc. This function is set up to look easily at typical outputs. initialize()” function is used internally by some imputation algorithms for finding the missing values which are imputed with the mean for vectors of class “numeric”, also with the median for the vector of class “integers” and last but not least the mode for vectors of class “factor”. It initializes the missing values through a rough estimation of missing values in a vector according to its type. ColMeans() function along with sapply() function. It is always helpful to find the mean of the multiple columns. Wed can also find the mean of multiple columns through Dplyr functions. summarise_if() function along with is.numeric() function is used to get the mean of the multiple column. With the help of the summarise_if() function, the mean of numeric columns of the data frame is calculated. Str_count() : It count the number of patterns. Syntax= str_count(x, pattern) Str_locate() : It gives the location or position of the match. Syntax= str_locate(x, pattern)Str_extract() : It extract the text of the match. Syntax= Str_extract(x, pattern)Str_match() : It extract parts of the match defined by parenthesis. Syntax = str_match(x, pattern)Str_split() : It splits a string into multiple pieces. Syntax = str_split(x, pattern)t() function and by iterating over each value using Loops. seq() is called with the one unnamed numerical argument data of length 1, as a result, it returns an integer sequence from 1 to the value of the argument. In a question seq(4) is the command returns the integers 1,2,3,4. While seq_along(4) produces the vector of indices of a given factor. corrgram() function produces a graphical display of a correlation matrix. Its cells can be shaded or colored to show the correlation value. In corrgram() function the non-numeric column in the data will be ignored. R objects that are used to attaching and loading files in R.R editor by the dump function..txt files are used to store datasets. R uses theread.table() and write.table() function.>name <-c(“Peeter”,”Danny”)
>temp <-5
> repeat {
print(name)
temp <- temp +2
if(temp >11){
Break
}
}R is performed in the same way as in other languages. The three main decision-making statements contain:melt(). So, now we have data arranged in some order, if we want to aggregate the columns with similar company_name and age, then we should use the cast() function.Casted_data_set <- cast(new_data_set, company_name+age ~ variable, sum)x-axis and y-axis. The simple scatterplot is plotted using plot() function.plot(x,y,main,xlab,ylab,xlim,ylim,axes)​
plot(x = input$wt,y = input$mpg,
xlab = “Weight”,
ylab = “Mileage”,
xlim = c(2.5,5)
ylim = c(15,30)
main = “Weight vs Mileage”
)sink() function defines the direction of the output.#direct output to a file
sink(“myfile”, append = FALSE, split = FALSE)
#return output to the terminal sink()