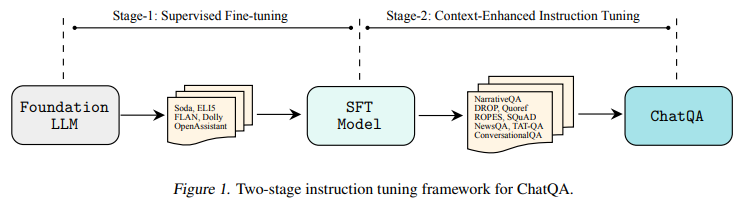
One of the variants, ChatQA-70B, outperforms GPT-4 in average scores across ten conversational QA datasets, a feat achieved without relying on synthetic data from existing ChatGPT models. This outstanding performance is a testament to the efficacy of the two-stage instruction tuning method employed by ChatQA.
In conclusion, ChatQA represents a significant leap forward in conversational question answering. This research addresses the critical need for improved accuracy in zero-shot QA tasks and highlights the potential of advanced instruction tuning methods to enhance the capabilities of large language models. The development of ChatQA could have far-reaching implications for the future of conversational AI, paving the way for more accurate, reliable, and user-friendly conversational models.