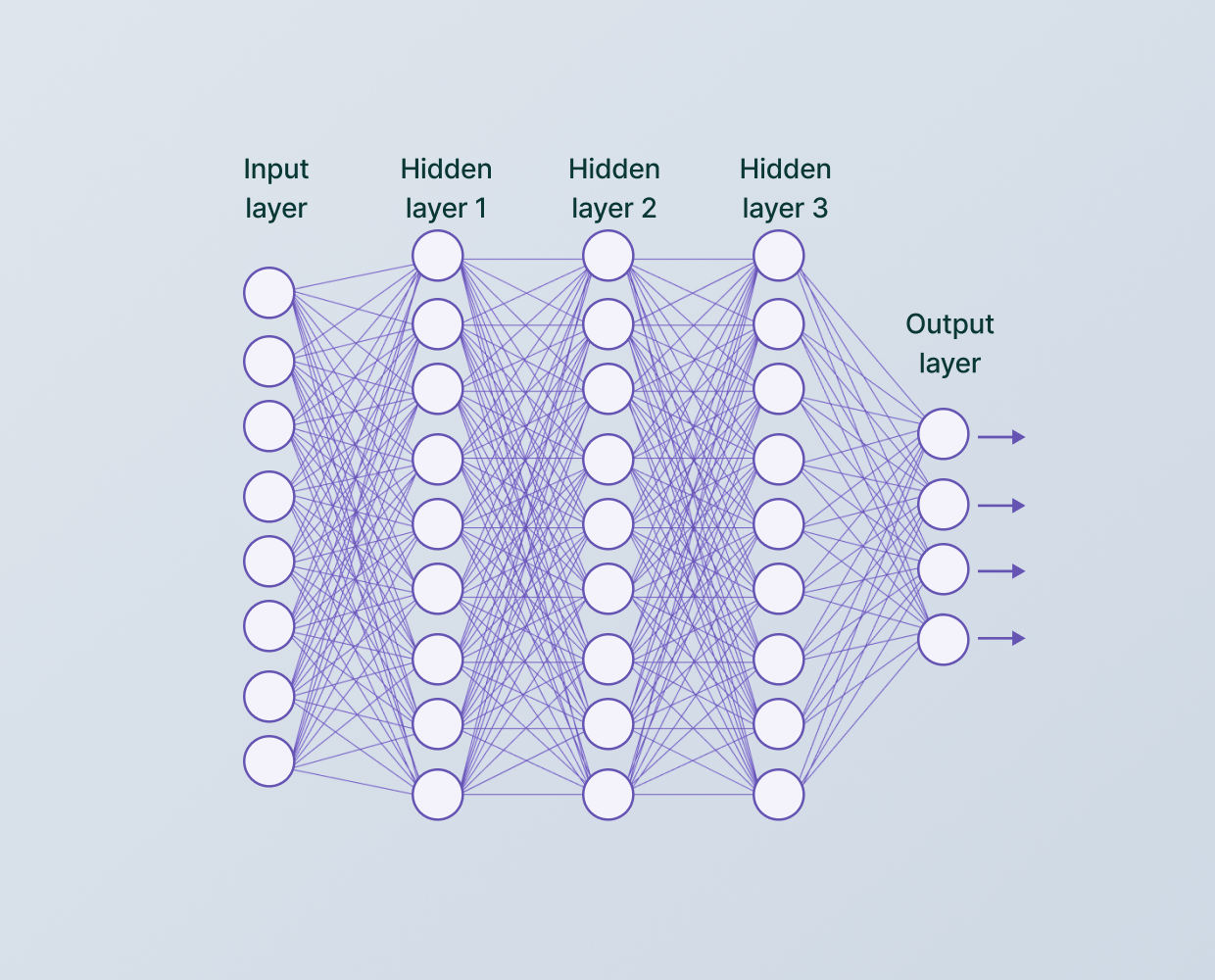
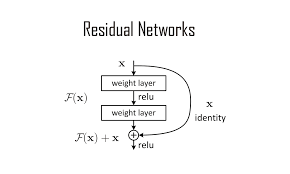
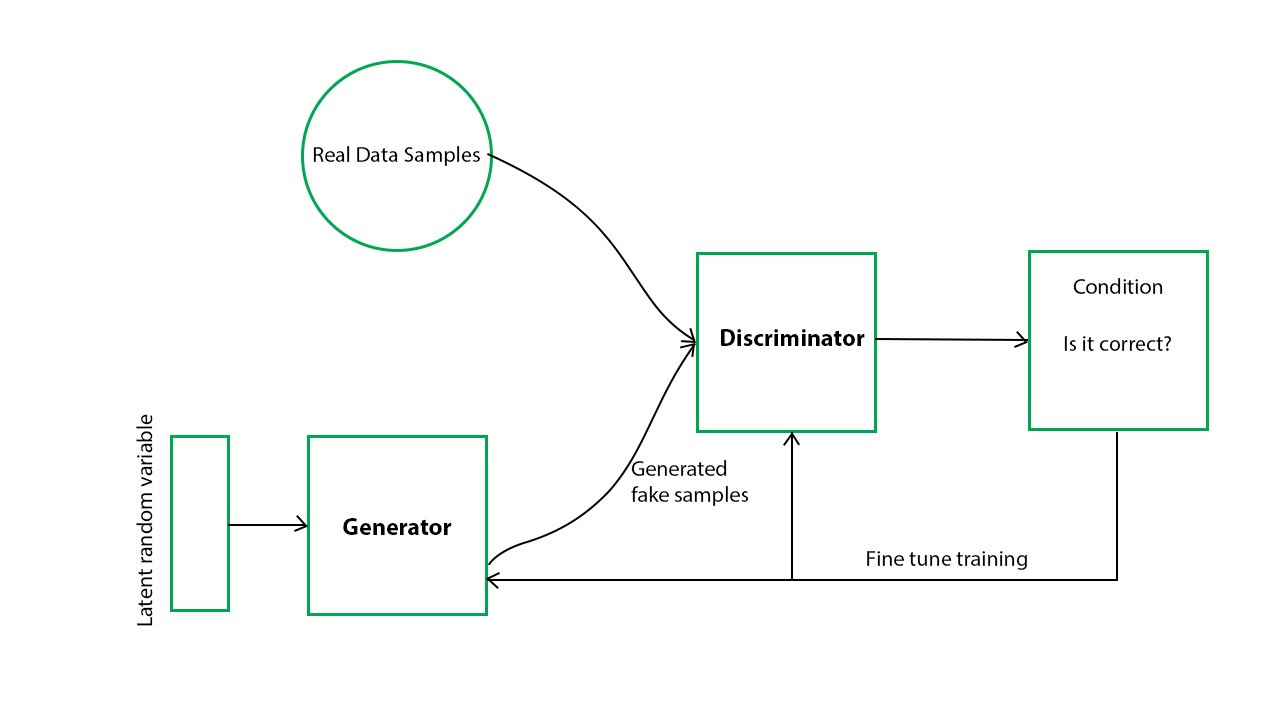
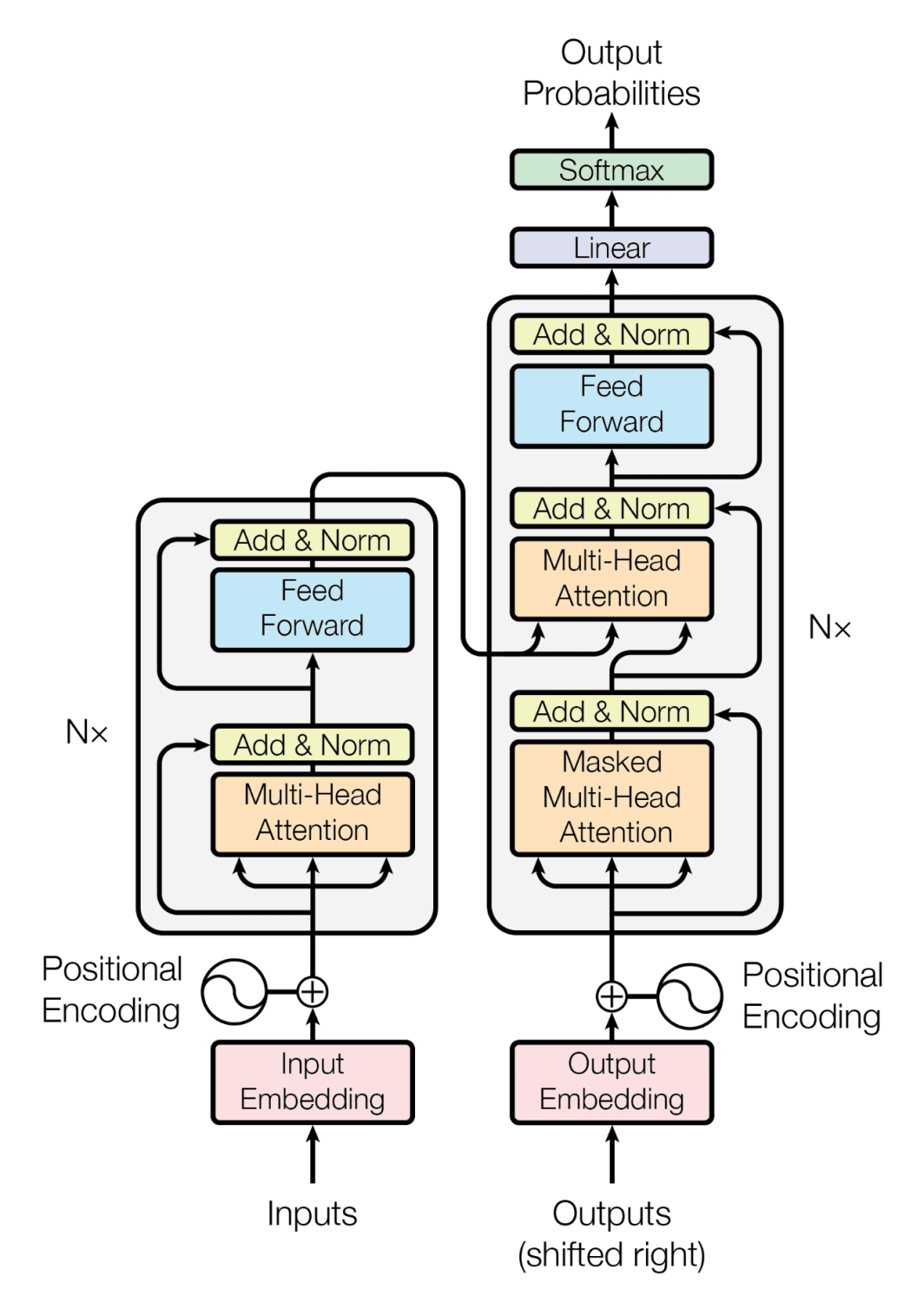
These models, relying on self-attention mechanisms, have shown impressive results, sometimes outperforming traditional CNN-based approaches.
Comparative Performance
While the choice of architecture can depend on the task at hand, it's crucial to understand that deeper networks like ResNet, InceptionNet, and transformer-based models typically provide better performance. However, they also come with a cost in terms of computational resources and can be overkill for simpler tasks. Therefore, the choice of architecture is a balance between the complexity of the task, computational resources, and the required accuracy.
Conclusion :
Deep learning architectures have significantly influenced the development and advancements in computer vision. As the field progresses, we are likely to see the advent of even more sophisticated and efficient architectures, pushing the boundaries of what's possible with computer vision.
Remember, while understanding and implementing these models, the key lies not only in knowing what these models are but also in comprehending the unique features, advantages, and potential drawbacks they bring to your specific project or research.
@
Sundar Balamurugan