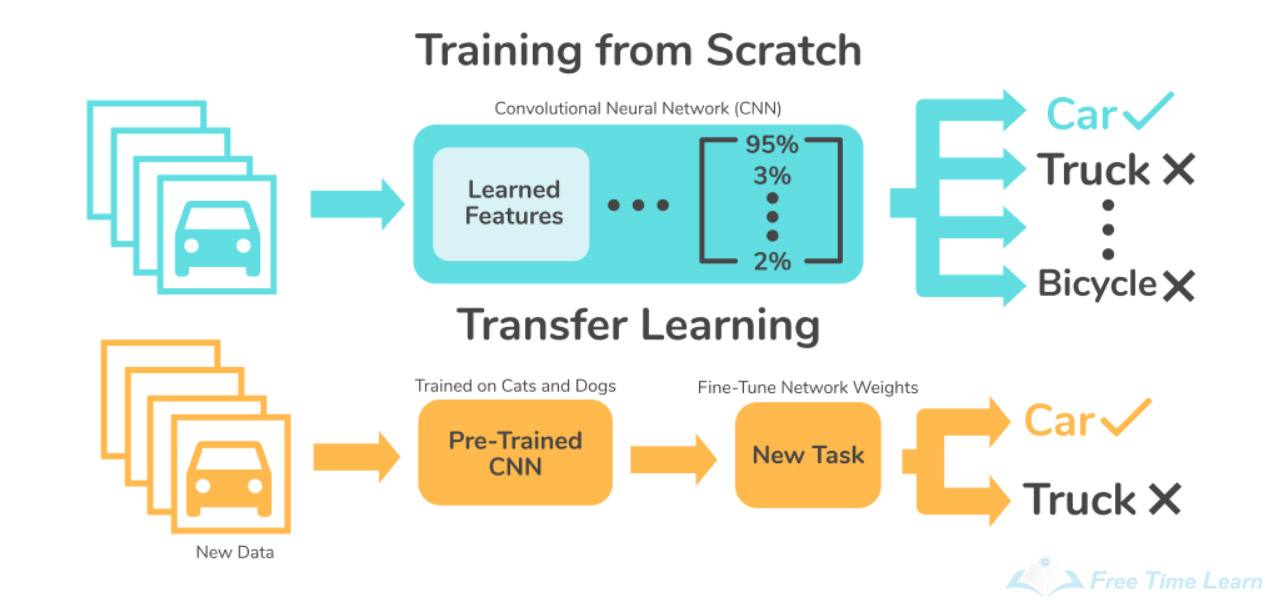
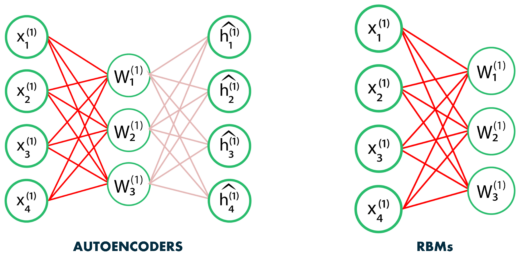
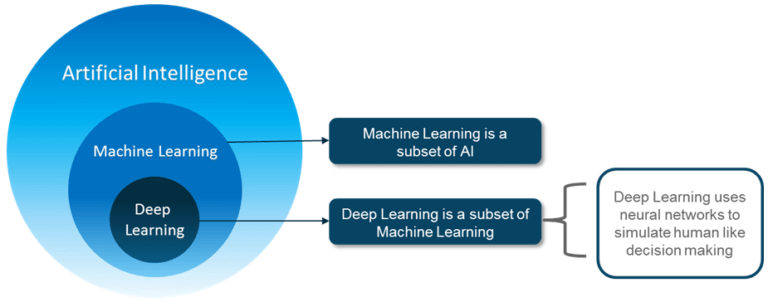
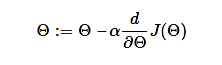Traditional machine learning refers to a set of algorithms and approaches that have been widely used for many years in a variety of applications, such as linear regression, logistic regression, decision trees, and random forests, among others. These algorithms make use of hand-engineered features and rely on feature engineering to extract relevant information from the data.
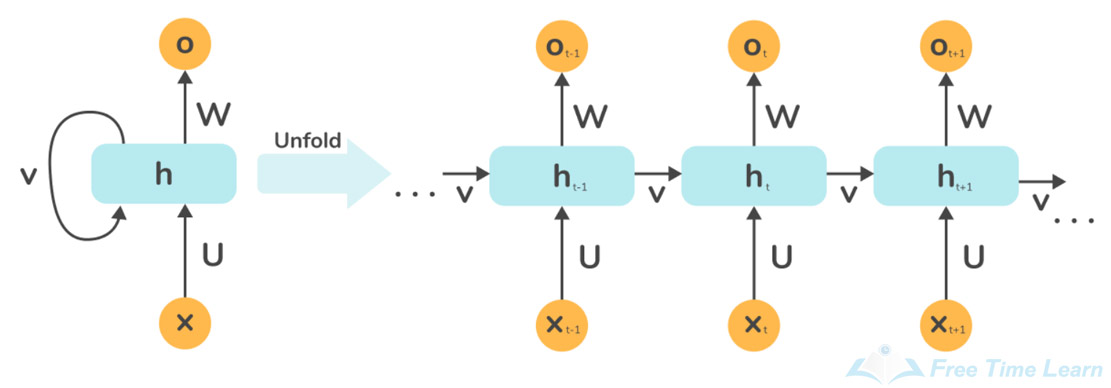
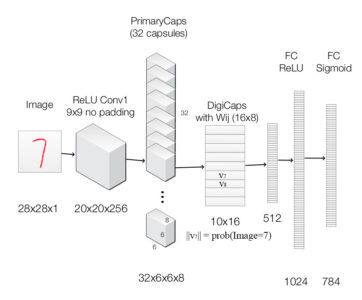
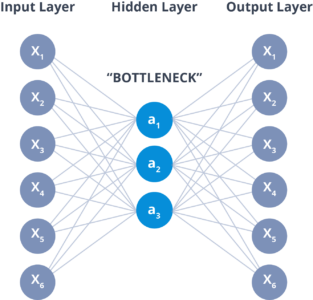
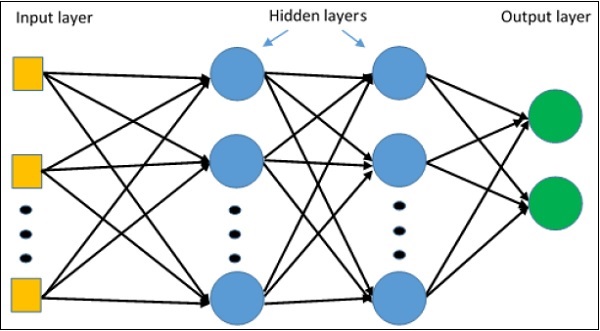
Deep learning, on the other hand, is a subfield of machine learning that uses artificial neural networks with multiple layers (hence "deep") to learn complex representations of the input data. In deep learning, the features are learned automatically by the network, rather than being hand-engineered by the programmer. This allows deep learning models to automatically extract high-level features from raw data, such as images, audio, and text, and to make predictions based on those features.
The main difference between
deep learning and traditional machine learning is the level of abstraction in the learned representations. Deep learning models learn hierarchical representations of the data, with each layer learning increasingly higher-level features. In contrast, traditional machine learning models typically only learn a single level of features.
Another key difference is the amount of data required to train a model. Deep learning models require large amounts of data to train effectively, while traditional machine learning models can often be trained with smaller amounts of data.
Simple Answer : Deep learning is a subfield of machine learning that uses deep artificial neural networks to learn high-level representations of the data, while traditional machine learning algorithms make use of hand-engineered features and require relatively small amounts of data to train.


.jpg)
.jpg)