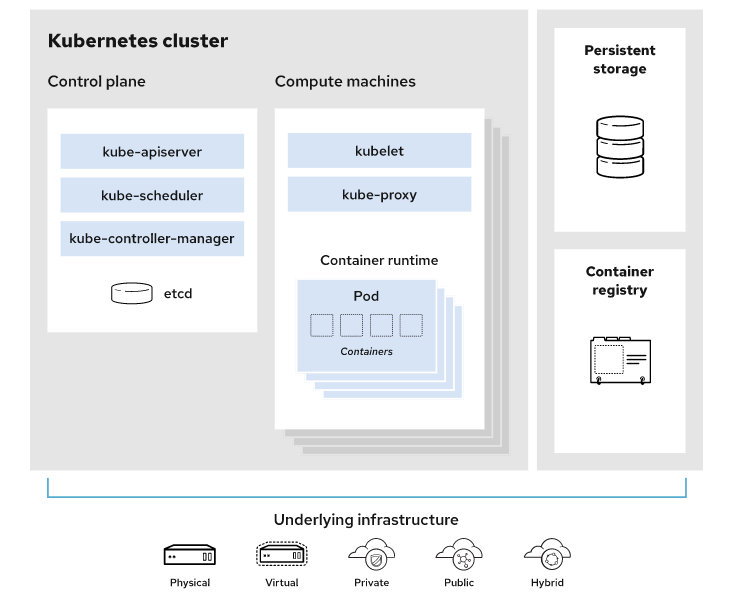
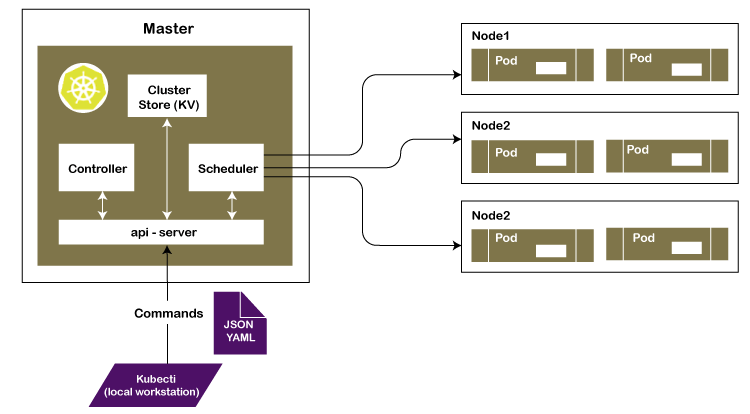
The primary advantage of using Kubernetes in your environment, especially if you are optimizing app dev for the cloud, is that it gives you the platform to schedule and run containers on clusters of physical or virtual machines (VMs).
More broadly, it helps you fully implement and rely on a container-based infrastructure in production environments. And because Kubernetes is all about automation of operational tasks, you can do many of the same things other application platforms or management systems let you do—but for your containers.
Developers can also create cloud-native apps with Kubernetes as a runtime platform by using Kubernetes patterns. Patterns are the tools a Kubernetes developer needs to build container-based applications and services.
With Kubernetes you can :
* Orchestrate containers across multiple hosts.
* Make better use of hardware to maximize resources needed to run your enterprise apps.
* Control and automate application deployments and updates.
* Mount and add storage to run stateful apps.
* Scale containerized applications and their resources on the fly.
* Declaratively manage services, which guarantees the deployed applications are always running the way you intended them to run.
* Health-check and self-heal your apps with autoplacement, autorestart, autoreplication, and autoscaling.
However, Kubernetes relies on other projects to fully provide these orchestrated services. With the addition of other open source projects, you can fully realize the power of Kubernetes. These necessary pieces include (among others) :
* Registry, through projects like Docker Registry.
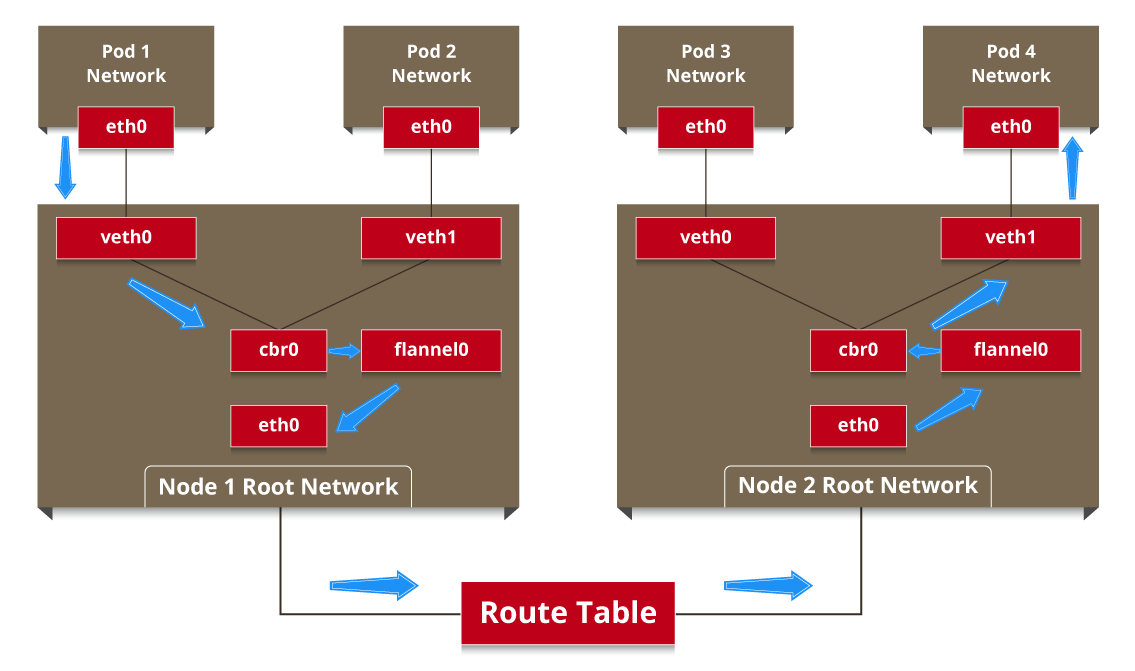
* Networking, through projects like OpenvSwitch and intelligent edge routing.
* Telemetry, through projects such as Kibana, Hawkular, and Elastic.
* Security, through projects like LDAP, SELinux, RBAC, and OAUTH with multitenancy layers.
* Automation, with the addition of Ansible playbooks for installation and cluster life cycle management.
* Services, through a rich catalog of popular app patterns.